
Detta är den tredje artikeln i en serie fristående artiklar som jag skrev i början av 2015 med anledning av en diskussion som uppstått kring Personuppgiftslagen (PUL) och vad som är en “databas” i lagens bemärkelse. Artiklarna är löst tematiskt sammanhållna och behandlar var för sig praktiska, juridiska och programmeringstekniska aspekter av hur man mycket enkelt kan använda en uppsättning Wordfiler som en fullt fungerande databas.
Läs även gärna de övriga artiklarna i serien:
- PUL och Worddatabaser (juridiska och politiska aspekter)
- Att skapa en databas från Wordfiler: Läsa in data (programmering och datainläsning)
- Att skapa en databas från Wordfiler: städa upp i databasen (databearbetning)
- Efterord: Liberal tolkning av PUL och bristande teknisk kunskap hos svenska domstolar? (kommer inom kort)
Inledning
I tidigare inlägg har jag diskuterat hur enkelt det är att sätta upp en databas bestående av ett antal wordfiler med hjälp av lite enkla scraping-verktyg. Men den databas vi tog fram senast är visserligen fullständig, men ganska rörig. I denna artikel visar jag hur man snabbt kan skapa lite struktur i en sådan, förhållningsvis ostrukturerad databas. Precis som i föregående inlägg kommer jag att använda mig av R för att visa hur detta kan gå till.
Skapa tidy data
Den dokumentdatabas vi skapade i förra inlägget har tre kolumner: docnum, som fungerar som primärnyckel i databasen, header och text.
Vi börjar med att titta närmare på header-kolumnen. Den visar oss vilka rubriker som finns i de olika dokumenten. Låt oss se vilka som ingår i varje dokument:
by(dokumentdata, dokumentdata$docnum, FUN = function(x) unique(x$header))> dokumentdata$docnum: 1
> [1] "Personuppgifter" "Personalia" "Brottmål" "Ekonomi"
> [5] "Övrigt"
> -------------------------------------------------------------------
> dokumentdata$docnum: 2
> [1] "Hemligt dokument" "Personalia" "Brottmål" "Ekonomi"
> [5] "Övrigt"
> -------------------------------------------------------------------
> dokumentdata$docnum: 3
> [1] "Hemligt dokument" "Personalia" "Brottmål" "Ekonomi"
> [5] "Övrigt"
> -------------------------------------------------------------------
> dokumentdata$docnum: 4
> [1] "Hemliga uppgifter för person med skyddad identitet"
> [2] "Personalia"
> [3] "Brottmål"
> [4] "Årsinkomster"
> [5] "Skulder"
> [6] "Övrigt"
> -------------------------------------------------------------------
> dokumentdata$docnum: 5
> [1] "Personuppgifter, person med skyddad identitet"
> [2] "Personalia"
> [3] "Brottmål"
> [4] "Ekonomi"
> [5] "Övrigt"
> -------------------------------------------------------------------
> dokumentdata$docnum: 6
> [1] "Loremipsumdolorsitamet, consecteturadipiscing elit, sed do eiusmodtemporincididunt ut labore et doloremagnaaliqua. Ut enim ad minimveniam, quisnostrudexercitationullamcolaborisnisi ut aliquip ex eacommodoconsequat. Duisauteiruredolor in reprehenderit in voluptatevelit esse cillumdolore eu fugiatnulla pariatur. Excepteur sint occaecatcupidatat non proident, sunt in culpa quiofficiadeseruntmollitanim id est laborum"
> [2] "Personalia"
> [3] "Bolagsengagemang"
> [4] "Ekonomi"
> [5] "Brottmål"
> [6] "Övrigt"Det finns en del udda data här. Men en gemensam nämnare för nästan samtliga dokument är att de innehåller rubrikerna “Personalia”, “Ekonomi”, “Brottmål” och “Övrigt”. Ett av dokumenten, nr. 4, tycks dock ha ersatt “Ekonomi” med rubrikerna “Årsinkomster” och “Skulder”. Men det är inget vi inte kan åtgärda!
Ju större skillnaderna är mellan olika dokument, desto svårare kommer det såklart att bli att extrahera information om samtliga individer i databasen. I denna artikel gör vi antagandet att den information vi är ute efter är den som finns lagrad för samtliga individer, i detta fall uppgifter om personer, deras ekonomi (vi avgränsar oss till årsinkomster) och deras inblandning i brottmål. Dessutom kommer vi att spara alla eventuella kommentarer under “Övrigt” som en textsträng. Men vi hade lika gärna kunna varit ute efter andra data - ladda gärna ned dokumenten från mitt GitHub-repo och sök igenom dem själv!
Det viktiga nu är att skapa sig en uppfattning om hur data kan tänkas se ut. text-kolumnen innehåller hela stycken ur de olika Worddokumenten. Vilka är relevanta, och vad kan vi utvinna för information ur dem? För att kunna svara på dessa frågor behöver vi extrahera data kategori för kategori och undersöka dem lite närmare, och eventuellt göra mindre justeringar innan vi slutligen sparar data i färdiga relationstabeller.
Nu återstår bara att söka igenom databasen kategori för kategori och spara data i ett lättläst och “tidy” format.
Personalia
Vi börjar med den lättaste kategorin - personalia. Först plockar vi ut enbart de rader som har header == "Personalia":
personalia_raw <- dokumentdata %>%
filter(header == "Personalia") %>%
group_by(docnum)
print(personalia_raw, n = 12)> Source: local data frame [12 x 3]
> Groups: docnum
>
> docnum header text
> 1 1 Personalia Personnr: 234568-9843
> 2 1 Personalia Namn: Sven Svenljunga
> 3 2 Personalia Personnr: 123456-7890
> 4 2 Personalia Namn: Namn Namnsson
> 5 3 Personalia Personnr: 214365-8709
> 6 3 Personalia Namn: Charlie Charlieberg
> 7 4 Personalia Personnr: 661122-0033
> 8 4 Personalia Namn: Svinlaug S. Svinlaugsbäck
> 9 5 Personalia Personnr: 123456-7890
> 10 5 Personalia Namn:Anka Anksson
> 11 6 Personalia Personnr: 123456-7890
> 12 6 Personalia Namn: Vildsvin VildsvinsdotterPersonalia tycks vara ganska enhetligt strukturerade. Rader med namn tycks ofta (alltid?) inledas med texten “Namn:”, och personnummer följer alltid formatet YYMMDD-XXXX. Vi kan därför extrahera namn och personnr med hjälp av ytterligare filtrering och perl-liknande reguljära uttryck genom att söka efter de mönster jag beskrev ovan:
namn <- personalia_raw %>%
filter(str_detect(text, "namn" %>% ignore.case())) %>%
mutate(
# Extract all characters following the string "Namn:"
namn = str_extract_all(text, "(?<=namn:).*" %>% perl() %>% ignore.case())[[1]] %>%
# and then remove surrounding whitespace
str_trim()
) %>%
select(docnum, namn)
personnr <- personalia_raw %>%
filter(str_detect(text, "\\d{6}-\\d{4}" %>% perl())) %>%
# Extract strings on the form DDDDDD-DDDD
mutate(personnr = str_extract_all(text, "\\d{6}-\\d{4}" %>% perl())[[1]]) %>%
select(docnum, personnr)Vi kan nu upprepa denna procedur för alla uppgifter vi är intresserade av.
Ekonomi
Nästa steg är uppgifter om årsinkomster. Som vi såg ovan innehåller alla dokument utom ett rubriken “Ekonomi”, medan ett av dokumenten istället hade rubriken “Årsinkomster”. Vi måste alltså ta med båda två dessa i vår sökning.
Precis som ovan börjar vi med att extrahera all ekonomidata och titta närmare på den:
ekonomi_raw <- dokumentdata %>%
filter(header == "Ekonomi" | header == "Årsinkomster") %>%
group_by(docnum)
ekonomi_raw$text> [1] "Årsinkomst 2013: 300 000 kr"
> [2] "Inkomst 2012 – 250 000"
> [3] "Fem ärenden hos inkasso under 2012"
> [4] "Årsinkomst 2013: 514 000 kr"
> [5] "2012: 123 000 kr"
> [6] "Skulder: 141 000 kr"
> [7] "Kronofogden: 3st betalningsanmärkningar 2011-2012"
> [8] "Årsinkomst 2013: 45 000:-"
> [9] "2011 tjänade personen 537019 kr"
> [10] "Inga skulder"
> [11] "Kronofogden: inga anmärkningar"
> [12] "2013: 450 000"
> [13] "2012: 420 000"
> [14] "2011: 415 000"
> [15] "2010: 360 000"
> [16] "2009: 300 000"
> [17] "Årsinkomst: 220 000 (2010), 230 000 (2011), 231 456 (2012), 240 071 (2013), 260 765 (2014)"
> [18] "Inga skulder. Kreditvärdighet 8,5 av 10."
> [19] "Årsinkomst 2014: 514 100 kr"
> [20] "Vildsvin är helt skuldfri"Vi kan notera fyra saker om vårt data:
- I vårt data har inkomstuppgifter alltid fem eller sex siffror, och ibland används ett mellanslag som tusentalsavgränsare.
- Årsuppgifter är alltid fyra siffror långa och börjar alltid med “20”.
- Inkomstuppgifter och årsuppgifter förekommer alltid på samma rad.
- Rad 17 har fem inkomstuppgifter OCH årsuppgifter på samma rad. Vi måste separera dessa till fem olika rader innan vi kan lagra dem i vårt dataset.
Vi börjar med att extrahera data för alla dokument utom nummer 5, där raden med fem inkomstuppgifter finns.
# Extract income data
inkomster <- ekonomi_raw %>%
filter(str_detect(text, "\\d{2,3}(\\s)?\\d{3}" %>% perl())) %>%
mutate(
ar = str_extract(text, "20\\d{2}" %>% perl()),
inkomst = str_extract(text, "\\d{2,3}(\\s)?\\d{3}" %>% perl())
)Vi fortsätter sedan med att separera inkomstuppgifter för dokument nr 5 och sedan lägga till dem till vårt nyskapade dataset.
# Separate the single row for document 5 into five separate rows
ink5 <- ekonomi_raw$text[ekonomi_raw$docnum == 5][[1]]
yrs <- str_extract_all(ink5, "(?<=\\()\\d{4}(?=\\))" %>% perl())[[1]]
ink <- str_extract_all(ink5, "\\d{2,3}(\\s)?\\d{3}" %>% perl())[[1]]
inkomster_5 <- data_frame(
docnum = 5,
ar = yrs,
inkomst = ink,
header = "Ekonomi"
)
# Replace data for document 5 with the munged data
# and convert the string "XXX XXX" into an integer
inkomster <- inkomster %>%
filter(!is.na(ar), docnum != 5) %>%
bind_rows(inkomster_5) %>%
select(-text, -header) %>%
mutate(inkomst = inkomst %>% str_replace_all("[[:blank:]]", "") %>% as.integer())Brottmål
Vi upprepar proceduren för brottmålsinblandning:
## Brottmål
brottmal_raw <- dokumentdata %>%
filter(header == "Brottmål") %>%
group_by(docnum)
brottmal_raw$text> [1] "Mål 471-546 (frikänd)"
> [2] "Kommentar om att personen aldrig varit dömd i brottmål"
> [3] "Mål 123-65"
> [4] "Kommentar om att personen varit dömd i brottmål"
> [5] "Mål 555-55"
> [6] "Kommentar om att personen varit dömd i brottmål"
> [7] "Inga brottmål"
> [8] "Kommentar: Svinlaug är helt straffri."
> [9] "Mål 632-632: Åtalad för snatteri men frikänd"
> [10] "Mål 871-192: Åtalad för uppseendeväckande beteende men frikänd"
> [11] "Mål 736-928: Dömd för grov stöld till dagsböter och 2 månaders villkorlig dom."
> [12] "Loremipsumdolorsitamet, consecteturadipiscing elit, sed do eiusmodtemporincididunt ut labore et doloremagnaaliqua. Hovrättsmål987-654aliqua. Excepteur sint occaecatcupidatat non proident, sunt in culpa quiofficiadeseruntmollitanim id est laborum"
> [13] "Loremipsumdolorsitamet, consecteturadipiscing elit, sed do eiusmodtemporincididunt ut labore et doloremagnaaliqua. Ut enim ad minimveniam, quisnostrudexercitationullamcolaborisnisi ut aliquip ex eacommodoconsequat.Duisauteiruredolor in reprehenderit in voluptatevelit esse cillumdolore eu fugiatnulla pariatur. Excepteur sint occaecatcupidatat non proident, sunt in culpa quiofficiadeseruntmollitanim id est laborummål 123-456 i hovrätten."
> [14] "Kommentar om att personen är straffri."Det här datat har helt klart en hel del brödtext i sig. Denna hade kunnat vara intressant i något annat sammanhang men just nu är vi som sagt bara intresserade av att veta vilka brottmål personerna varit inblandade i.
Jag har ingen som helst aning om hur ett register över inblandning i brottmål kan tänkas se ut i verkligheten, men mitt intryck är att brottmålen som registreras i just dessa dokument alltid är diarieförda med en kod på formatet [X]XX-XXX, alltså två eller tre siffror följda av ett mellanslag och sen tre siffror till. Vi extraherar därför dessa data:
# Filter out court cases
brottmal <- brottmal_raw %>%
filter(str_detect(text, "\\d{3}-\\d{2,3}")) %>%
mutate(inblandad_i_mal = str_extract(text, "\\d{3}-\\d{2,3}")) %>%
select(docnum, inblandad_i_mal)Kommentarer
Slutligen extraherar vi också all text som finns lagrad under “Övrigt” i dokumenten, mest för att visa att vi kan:
ovrigt <- dokumentdata %>%
filter(header == "Övrigt") %>%
select(docnum, kommentar = text)Sammanställning av samtliga data till en databas
Nu är vi nästan klara! Allt vi behöver göra är att lägga ihop alla de små prydliga dataset vi just skapat till en riktig, välstrukturerad databas. Som tur är har vi använt variabeln docnum som nyckel när vi skapat alla våra småtabeller, så vi kan återanvända den för att skapa en sorts primärnyckel i vår databas.
# Put everything together into a proper database
persondatabas <- namn %>%
left_join(personnr, by = "docnum") %>%
left_join(ovrigt, by = "docnum")För att se uppgifter om ekonomi eller brottmålsinblandning får vi lägga till dessa också, men om vi gör detta tappar vi principen “ett dokument, en rad”. Nedan ger jag ändå ett exempel på hur man kan göra om man vill följa principen om att lagra alla data i ett och samma dataset.
# Adding income and court case data creates more than one row per person
persondatabas_stor <- persondatabas %>%
left_join(inkomster, by = "docnum") %>%
left_join(brottmal, by = "docnum")Och voila! Vi har nu skapat vår egen prydliga, välstrukturerade databas med data uppdelade per person. Databsen har en primärnyckel, är trevlig att titta på och lätt att söka i.
Som avslutning kan vi titta på två exempel på hur en sådan databas skulle kunna användas på “riktigt”, t.ex. för att göra olika typer av integritetskränkande sökningar. Låt oss först anta att vi vill veta vem som hade högst och lägst inkomster av alla personer i databasen. Vi utgår då från den senaste kända inkomstuppgiften för varje person:
persondatabas %>%
# Only keep the columns we're interested in
select(-kommentar) %>%
# Join with income data
left_join(inkomster, by = "docnum") %>%
# Last year per person only
filter(ar == max(ar)) %>%
# Only keep top and bottom income holders
ungroup() %>%
filter(inkomst == max(inkomst) | inkomst == min(inkomst))> Source: local data frame [3 x 5]
>
> docnum namn personnr ar inkomst
> 1 3 Charlie Charlieberg 214365-8709 2013 45000
> 2 6 Vildsvin Vildsvinsdotter 123456-7890 2014 514100
> 3 6 Vildsvin Vildsvinsdotter 123456-7890 2014 514100Vildsvin Vildsvinsdotter är alltså den person med den högsta inkomsten i databasen, och Charlie Charlieberg är den med lägst inkomst.
Som ett andra exempel, låt oss anta att vi vill göra en scatter plot över relationen mellan inkomst och hur många brottmål man varit inblandad i. I detta fall använder vi oss av genomsnittet av personernas kända årsinkomster istället.
library("ggplot2")
library("scales")
persondatabas %>%
group_by(docnum, namn, personnr) %>%
select(-kommentar) %>%
left_join(inkomster, by = "docnum") %>%
summarise(medelinkomst = mean(inkomst)) %>%
left_join(brottmal, by = "docnum") %>%
group_by(docnum, namn, personnr, medelinkomst) %>%
summarise(antal_brottmal = sum(!is.na(inblandad_i_mal))) %>%
ggplot(aes(x = medelinkomst, y = antal_brottmal, color = namn)) +
geom_point(size = 10) +
labs(title = "Medelinkomst vs inblandning i brottmål (fiktiva data)", x = "Medelinkomst", y = "Antal brottmål 2010-2014") +
scale_color_brewer(palette = "Set1") +
scale_x_continuous(labels = comma)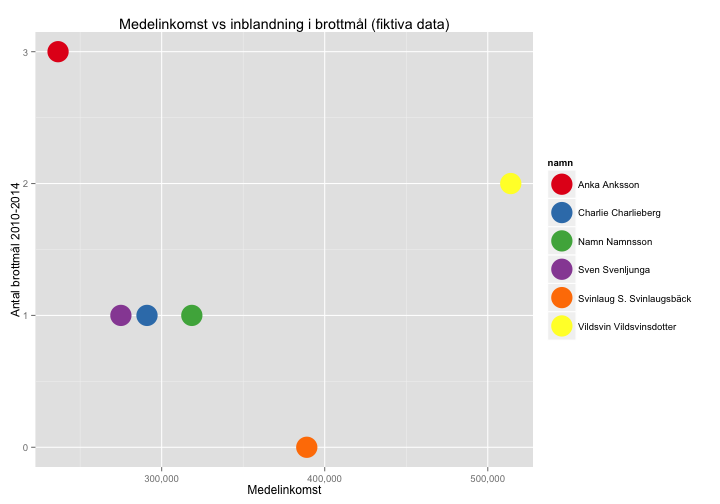
Så de med lägst och högst inkomster i databasen är alltså de som varit inblandade i flest brottmål. Intressant!
Avrundning
Mitt experiment där jag försökte använda en samling Worddokument som en databas är avslutat. Resultatet: det är ungefär lika enkelt att använda Worddokument som databas som det är att scrapa en webbsida, eller att lära sig lite SQL och skriva några queries. Koden i detta och föregående inlägg tog mig i runda slängar 3 timmar att skriva inklusive felsökning.
Avsikten har varit att ge ett konkret, förhoppningsvis lättläst exempel på detta. Det finns naturligtvis flera. Som jag nämnde i inledningen av detta experiment finns det nog många som skulle valt ett helt annat tillvägagångssätt men ändå nått ungefär samma, eller ett bättre, resultat.
En av poängerna jag vill göra med detta är att det är viktigt att förhålla sig kritisk till hur svårtillgänglig information faktiskt är bara för att man har lagrat den på ett obskyrt sätt. Jag tror inte att de flesta som arbetar med Worddokument har för avsikt att använda dem som en databas, men icke desto mindre är det väldigt lätt att göra just detta om man bara besitter lite rudimentära programmeringsfärdigheter.
I nästa inlägg ska jag försöka göra mitt bästa för att knyta ihop säcken kring detta resonemang.